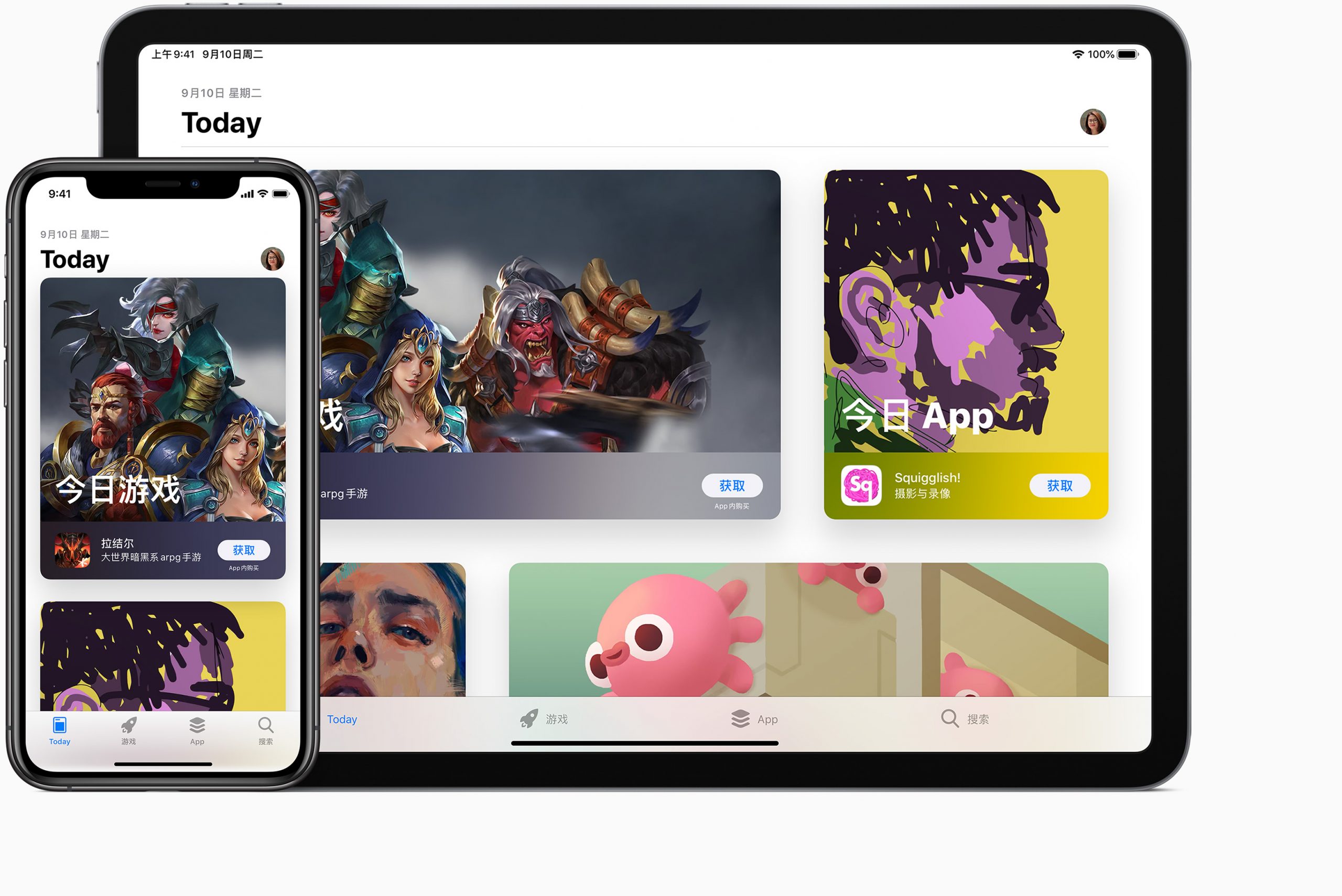
在 Meta 年度 Connect 會議中,Meta 宣佈即將在 WhatsApp 平台開放多項由 AI 驅動的新功能。這些新功能目的在於提升用戶在使用 WhatsApp 時的創造力、生產力和娛樂性。 Meta 表示,生成式 AI 的應用將開啟全新可能性,並讓全球的 WhatsApp 用戶得以充分利用這項新興技術。該公司透露,這些新功能是「漫長實驗之路」的第一步,並且已經讓部分用戶在對話中開始進行測試。…
根據《The Information》的報導,前 Apple 首席設計師 Jony Ive 正在與 OpenAI 的 CEO Sam Altman 討論一個全新的「AI 硬體」計劃。目前尚不清楚這個裝置將會是什麼,或將具備何種功能,但熟悉這個對話的消息來源指出,他們希望創造一個「AI 時代的新硬體」。值得一提的是,軟銀(SoftBank) 的 CEO 孫正義也參與了…
著名蘋果分析員郭明錤近日發佈一份有關 Apple Vision Pro 的報告,其中揭示了該產品在未來幾年的市場表現可能低於預期。 明年出貨量極少 根據郭明錤與部分零組件供應商的交流,預估 Vision Pro 在 2024 年的出貨量最多可能只有 40–60 萬部,這一數字遠少於市場普遍預計的 100 萬部以上。郭明錤認為,除非 Apple 顯著降價…
近日,有些 iPhone 15 Pro 及 Pro Max 用戶投訴 iPhone 15 Pro 系列有「過熱問題」。而知名蘋果分析員郭明錤指出,根據他的調查 iPhone 15 Pro系列的過熱問題,與台積電的3nm製程無關,主要很可能是為了讓重量更輕故對散熱系統設計作出妥協,像是散熱面積較小、採用鈦合金影響散熱效果等。 預期Apple將會透過更新軟體修正此問題,但除非調降處理器效能,否則改善效果可能有限。若Apple 沒有妥善解決這個問題,可能會不利iPhone 15…
Apple 在日前更新的支援文件中指出,使用者的指紋可能會「暫時改變」iPhone 15 Pro 和 iPhone 15 Pro Max 的鈦合金框架顏色。幸運的是,Apple 表示這不是一個永久性問題,因為指紋可以像在其他 iPhone 上一樣被擦掉,以恢復原始的外觀。 Apple 解釋,皮膚上的油脂可能會暫時改變外側帶的顏色,但使用柔軟、微濕、不起毛球的布擦拭 iPhone 將會恢復其原始外觀。自從這些裝置上週公佈以來,社交媒體上已經流傳著 iPhone…