OpenAI 整合核心 AI 服務 打造桌面級超級應用程式
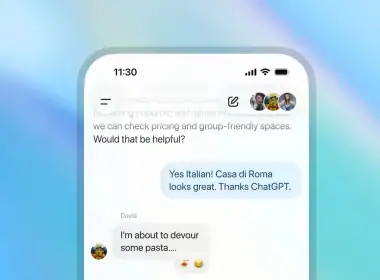
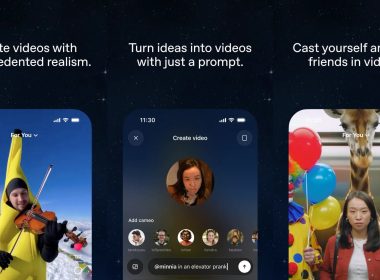
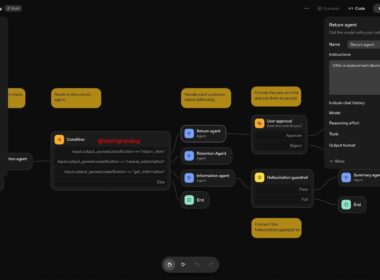
OpenAI 正在開發一款桌面級「超級應用程式」,旨在將其 ChatGPT 應用、Codex AI 編碼應用以及 Atlas AI 瀏覽器整合至單一平台。這項舉措目標是簡化產品策略,並解決公司內部因功能碎片化而導致的效率問題。 應用程式 CEO 點出碎片化挑戰 面臨產業競爭加劇 OpenAI 應用程式 CEO Fidji Simo 在一份備忘錄中表示,產品的碎片化「已拖慢我們的進度,並使得達成預期品質目標變得更困難」。儘管…