
日前,日本科技巨頭樂天(Rakuten)高調發布了號稱日本國內最大、性能最強的人工智慧模型——Rakuten AI 3.0。這款擁有近 7000 億參數的龐然大物,不僅被視為日本 AI 工程技術的重大里程碑,更獲得了日本政府「生成式 AI 開發支援計畫(GENIAC)」的資金挹注。
然而,發布後短短幾天內,這場技術盛宴卻演變成一場公關危機。開源社群的開發者們在檢視其程式碼後發現:這款被寄予厚望的「日本國產 AI」,其實是基於中國知名開源模型 DeepSeek-V3 進行微調(Fine-tuning)的產物。
重點文章
鐵證如山:開源社群的「法醫級」檢驗
樂天在官方新聞稿中,對於底層技術的描述顯得相當曖昧,僅表示該模型是「利用開源社群的最佳成果」並結合其獨有的日語數據訓練而成。但開發者們在開源平台 Hugging Face 上檢視 Rakuten AI 3.0 的模型檔案時,立刻發現了隱藏在細節中的魔鬼:
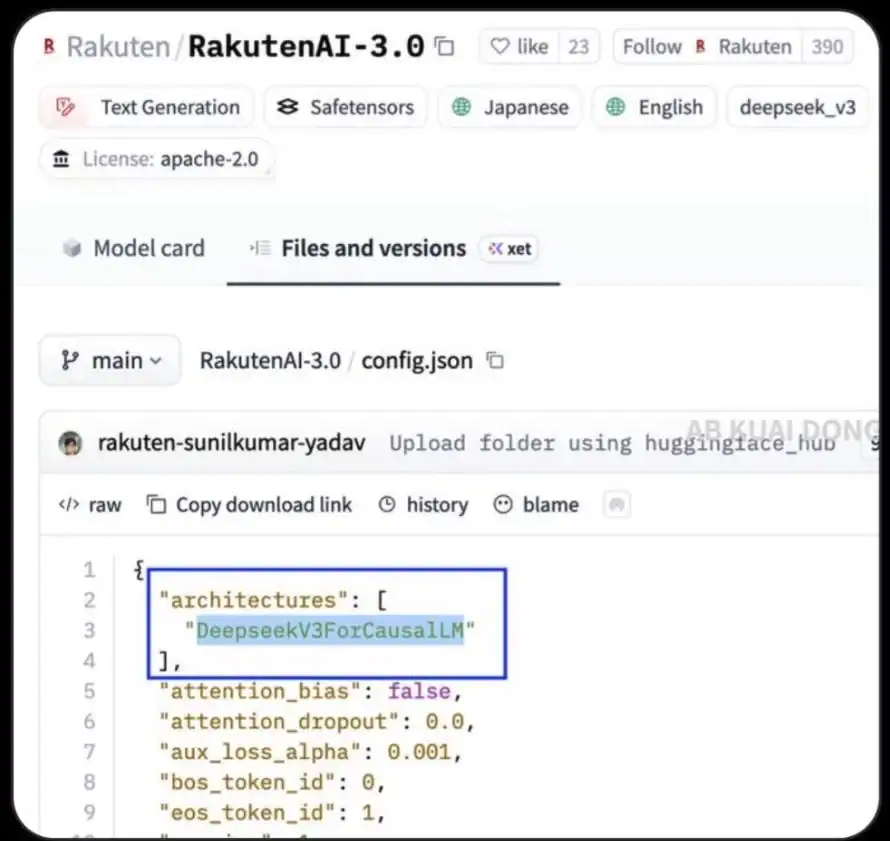
- 原始碼露餡: 模型的
config.json設定檔中,赫然寫著"model_type": "deepseek_v3"這一行程式碼。 - 架構特徵完全吻合: Rakuten AI 3.0 採用了與 DeepSeek-V3 完全相同的「混合專家(MoE)」架構,總參數為 6710 億,每次推論啟動的參數為 370 億。這種極其特殊的架構配置,猶如模型的指紋,直接證實了兩者的血緣關係。
錯在「缺乏透明度」
在 AI 產業界,站在巨人的肩膀上——也就是拿現有的頂級開源模型進行微調——是再正常不過的標準作業流程。這不僅能大幅節省算力成本,還能快速針對特定語言或垂直領域(如醫療、法律)進行優化。
那麼,為什麼樂天會遭到猛烈抨擊?答案在於「授權條款」與「透明度」。
DeepSeek-V3 採用的是極度寬鬆的 MIT 授權條款,允許任何企業進行商業化使用與修改,唯一且最基本的要求就是必須保留原始的版權聲明。然而,樂天最初在發布模型時:
- 移除了 DeepSeek 的授權檔案。
- 換上了自己的名稱,並以 Apache 2.0 授權條款重新發布。
這種行為在開源界被稱為「洗授權(License Laundering)」,引發了強烈的反彈。直到輿論發酵後,樂天才悄悄更新了 GitHub 與 Hugging Face 的儲存庫,補上了一個 NOTICE 檔案,正式承認了 DeepSeek 的版權歸屬。
本土化 AI 的捷徑與代價
從技術角度來看,樂天的策略其實非常聰明。DeepSeek-V3 擁有極其卓越的全球知識庫與推理能力,樂天利用自身龐大且高品質的日語數據生態系對其進行微調,成功打造出了一款在日語語境下表現極佳的 AI 模型。
然而,這起事件也給全球的 AI 開發者與政府敲響了警鐘。當企業拿著政府補助(如日本的 GENIAC 計畫),宣稱打造「本土自研」技術時,產業界需要更嚴格的審查機制來區分「從頭訓練(Train from scratch)」與「微調(Fine-tuning)」的差異。