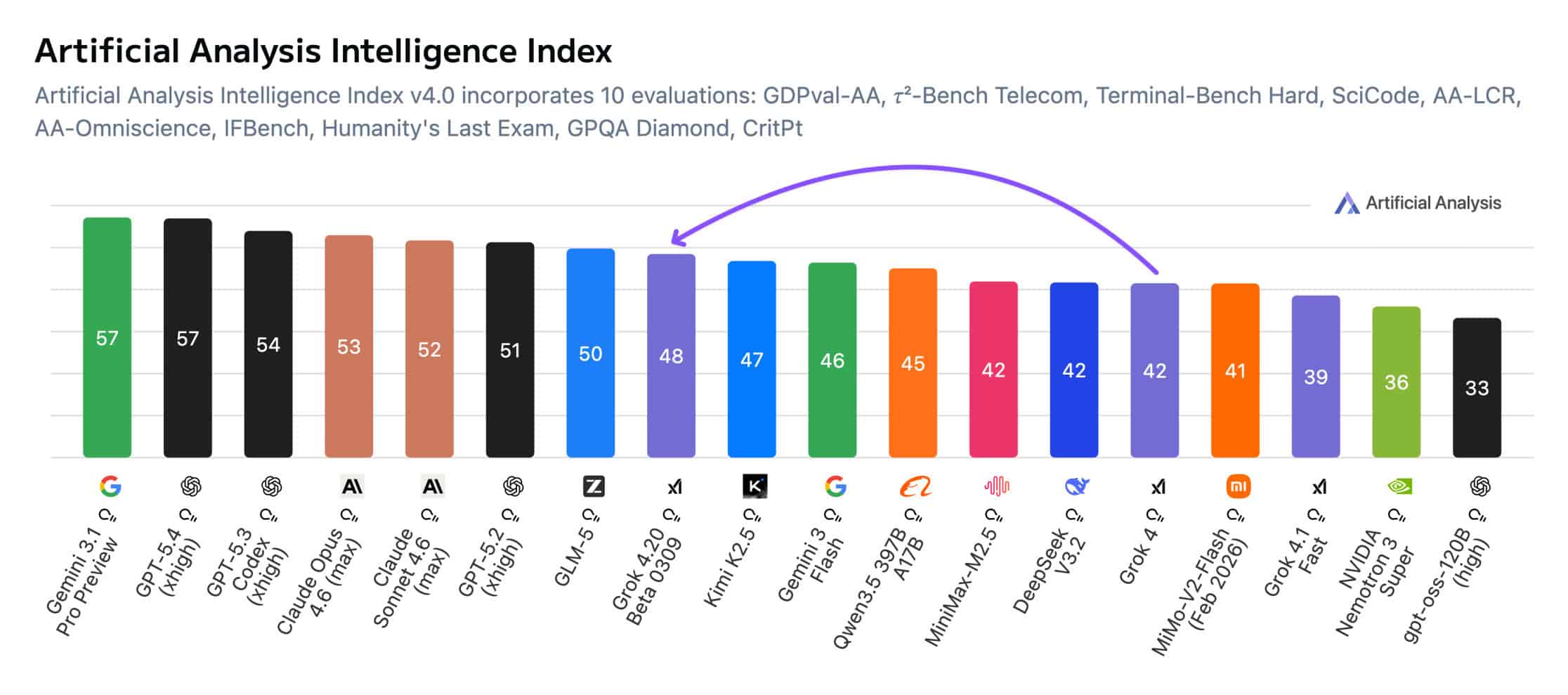
xAI 最新的 Grok 4.20 模型在基準測試中未能超越頂級 AI 模型,但其幻覺率卻是所有受測模型中最低的。根據 Artificial Analysis 的報告,Grok 4.20 Beta 在啟用推理功能後,於智能指數上獲得 48 分,顯著落後於 Gemini 3.1 Pro Preview 和 GPT-5.4 的 57 分,不過相較 Grok 4 仍有 6 分的進步。
重點文章
基準測試表現仍有差距
儘管 Grok 4.20 整體基準表現落後於主要 AI 實驗室的最新模型,但 xAI 為其發佈了三種 API 版本,包括具備推理、不具備推理以及多代理模式。該模型支援 200 萬詞元上下文視窗,每百萬詞元的價格為 2 或 6 美元,比 Grok 4 更便宜,在西方模型中價格也具備競爭力。
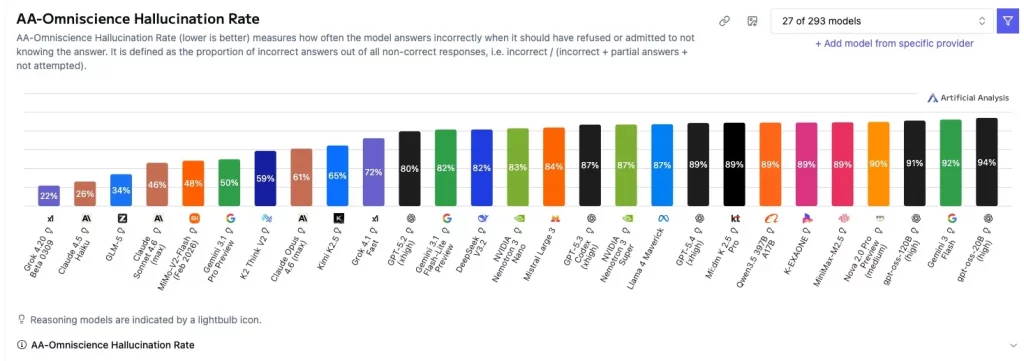
幻覺率創測試新紀錄
Grok 4.20 的主要特點在於其事實可靠性。根據 Artificial Analysis 的測試,Grok 4.20 在 AA Omniscience 測試中實現了 78% 的無幻覺率,創下新紀錄。這項測試評估模型在不知道答案時,是選擇編造內容,還是承認未知,同時也衡量其事實回溯能力。Grok 4.20 在沒有答案時,僅約五分之一的機率會給出錯誤資訊。