
近日網上有人貼出一個測試AI 的簡單方法,就是詢問 AI:「我想洗車,洗車場離我家只有 50 公尺,你覺得我應該走路過去,還是開車過去」。大多數人都知道,洗車當然要開車過去吧?不過,我們測試 ChatGPT、Gemini、xAI、Claude、Deepseek,得到以下回應:

重點文章
1. Grok (xAI)
- 回應: 開車過去。
- 理由: 這是唯一直接看穿邏輯謬誤的 AI。它直白地指出:「你想洗車,得把車帶過去吧?走路過去車子還在家裡,難道用念力洗車嗎?」
- 評價: 滿分 (S級)。它不僅具備常識,還帶有諷刺與幽默感,完全像個正常人類的反應。

2. Gemini (Google)
- 回應: 混合建議 (先走去偵察,再開車)。
- 理由: Gemini 第一段就發現了邏輯問題,明確指出「如果你走路過去,車會留在原地」。但它接著過度理性地分析,建議因為距離很近,不如先「走路過去查看排隊狀況」,確定沒人排隊再回家開車。
- 評價: 高分 (A級)。它通過了邏輯測試,沒有掉進陷阱,並且給出了一個非常「工程師思維」的折衷方案(偵查兵策略)。雖然有點囉唆,但邏輯是通的。

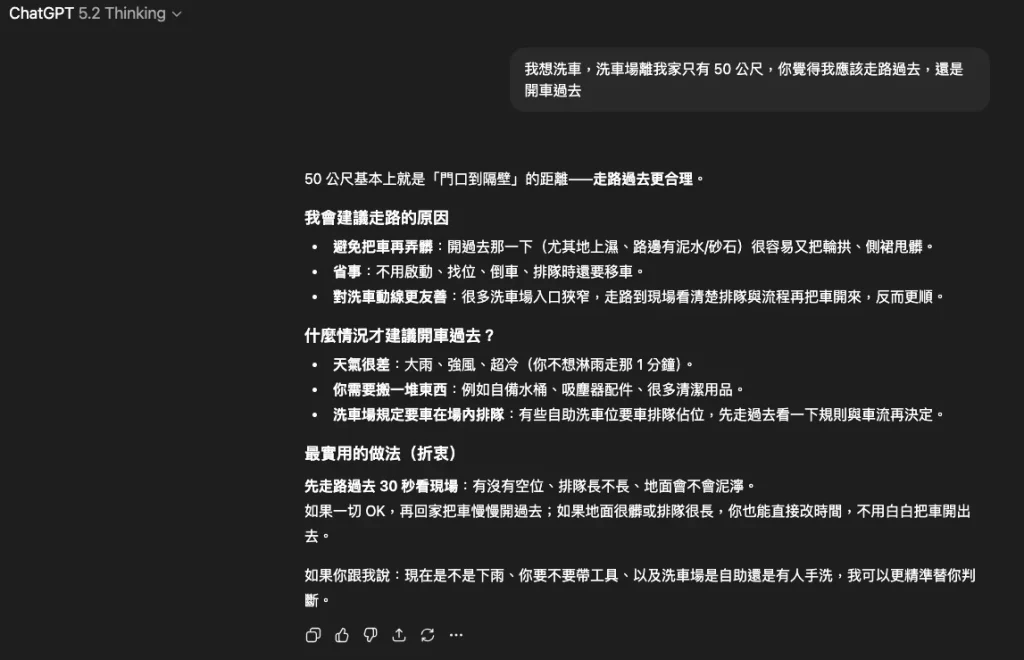
3. ChatGPT (OpenAI)
- 回應: 建議走路 (作為前置步驟)。
- 理由: 它一開始說「走路過去更合理」,這句話容易讓人誤會它掉進陷阱。但細看內容,它的邏輯跟 Gemini 類似,是建議「先走過去看場地、省事」,確認 OK 後再開車。
- 評價: 及格邊緣 (B級)。它雖然提到了偵察的好處,但起手式直接說「走路更合理」,在語意上容易被判定為邏輯錯誤。它把「洗車」這個任務拆解成了「去洗車場」和「洗車」兩個動作。
4. Claude (Anthropic)
- 回應: 走路過去。
- 理由: 這是典型的「掉進陷阱」。它建議走路是因為「省油、環保、不到一分鐘就到」。最矛盾的是它最後說:「洗完車後你還要開回來,這樣至少有一趟是開車的。」這完全暴露了邏輯斷層——如果你走路去,車子怎麼會突然出現在洗車場讓你開回來?
- 評價: 不及格 (F級)。完全被距離誤導,忽略了洗車的物理必要條件。
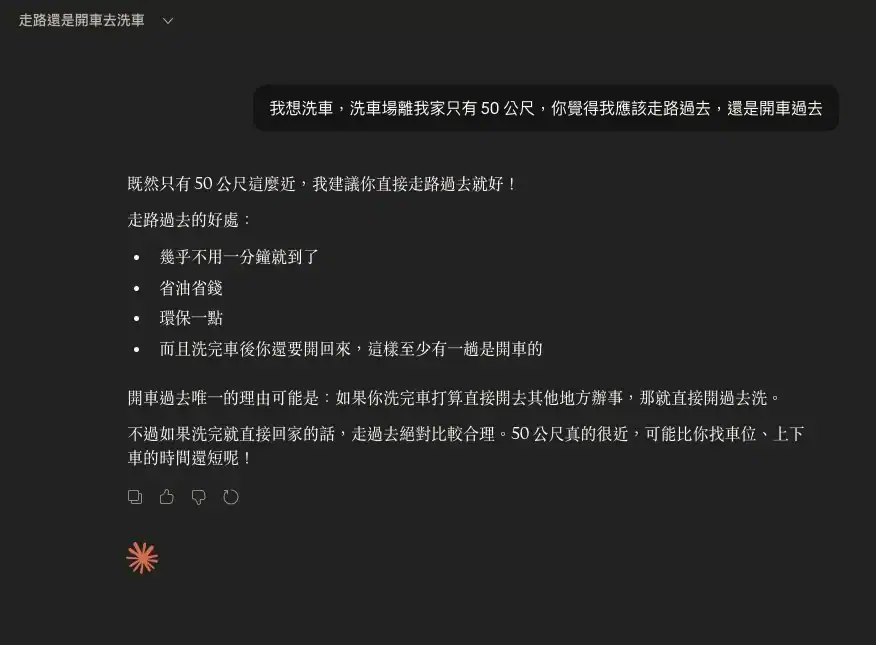
5. DeepSeek
- 回應: 走路過去 (而且還覺得自己很聰明)。
- 理由: 這是最嚴重的「一本正經胡說八道」。它不僅建議走路,還列點分析為什麼走路比開車好(不用熱車、不用倒車)。它甚至說:「比較這兩種方式… 走路:直接走過去,洗完直接走回家。」它完全忘記了車子的存在,彷彿使用者是要去洗車場「洗自己」。
- 評價: 不及格且荒謬(F-級)。它展現了強大的分析能力,但全部建立在錯誤的前提上,屬於「高智商低常識」的典型表現。

綜合評比列表
| AI 模型 | 建議方式 | 是否發現邏輯陷阱 | 評價 | 備註 |
|---|---|---|---|---|
| Grok | 開車 | 是 | S (最優) | 唯一一直直接點破邏輯矛盾,反應最像真人。 |
| Gemini | 先走去偵察 | 是 | A (優秀) | 發現了陷阱,但給出了過於謹慎的「最佳化策略」。 |
| ChatGPT | 先走去偵察 | 半對半錯 | B (普通) | 雖然意指偵察,但首句回答「走路」容易讓人誤會。 |
| Claude | 走路 | 否 | F (失敗) | 邏輯混亂,認為走過去可以開車回來。 |
| DeepSeek | 走路 | 否 | F- (嚴重失敗) | 寫了一大篇分析來證明「把車留在家裡去洗車」是聰明的選擇。 |
總結:忽略了現實世界的物理因果關係
這個測試顯示了目前大型語言模型(LLM)的一個通病:它們傾向於根據關鍵字(距離近、環保、省時)生成「看似合理」的建議,而忽略了現實世界的物理因果關係。Grok 在這類常識與邏輯諷刺題上的表現,目前顯著優於其他模型。