
Anthropic 發佈了其最新的頂級模型 Claude Opus 4.5。 該公司表示,該模型在軟件工程基準測試中創下紀錄,運行效率更高,並為 Claude 平台增加了新的控制和代理功能。

重點文章
效能提升與價格調整
在 Sonnet 4.5 發佈兩個月後,Anthropic 推出了其下一個旗艦模型:Claude Opus 4.5。 Anthropic 將其描述為世界上最強大的編程、自主代理和電腦控制模型,在電子表格編輯、深度研究和幻燈片創建等日常任務中均有所提升。 Opus 4.5 的定價為每百萬輸入 tokens 5 美元,每百萬輸出 tokens 25 美元,此舉旨在應對市場上日益增長的價格壓力。相較之下,5 月發佈的 Opus 4 定價為每百萬輸入 tokens 15 美元和每百萬輸出 tokens 75 美元,因此 Opus 4.5 的價格降幅約為三分之二。

基準測試與實際應用
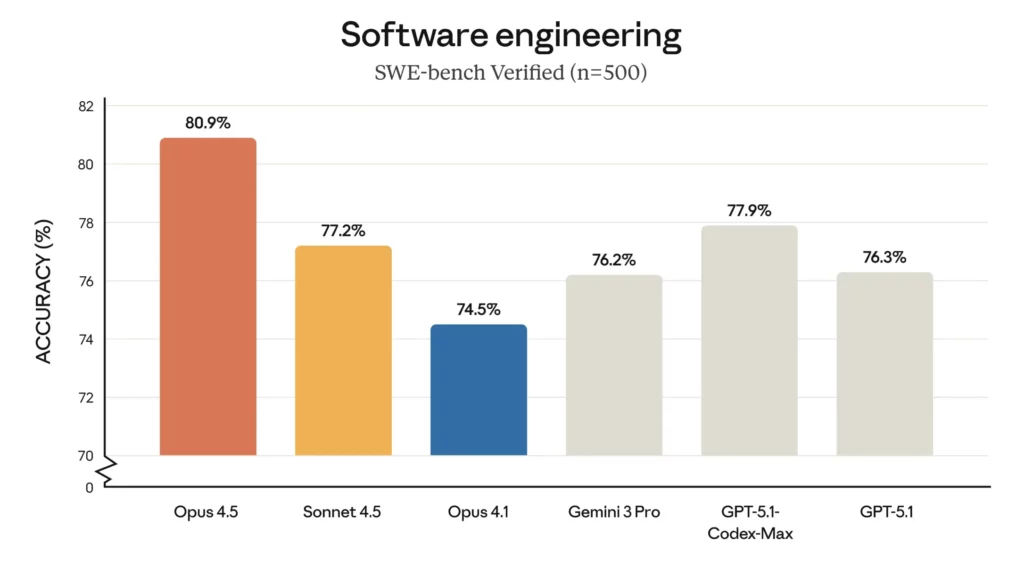
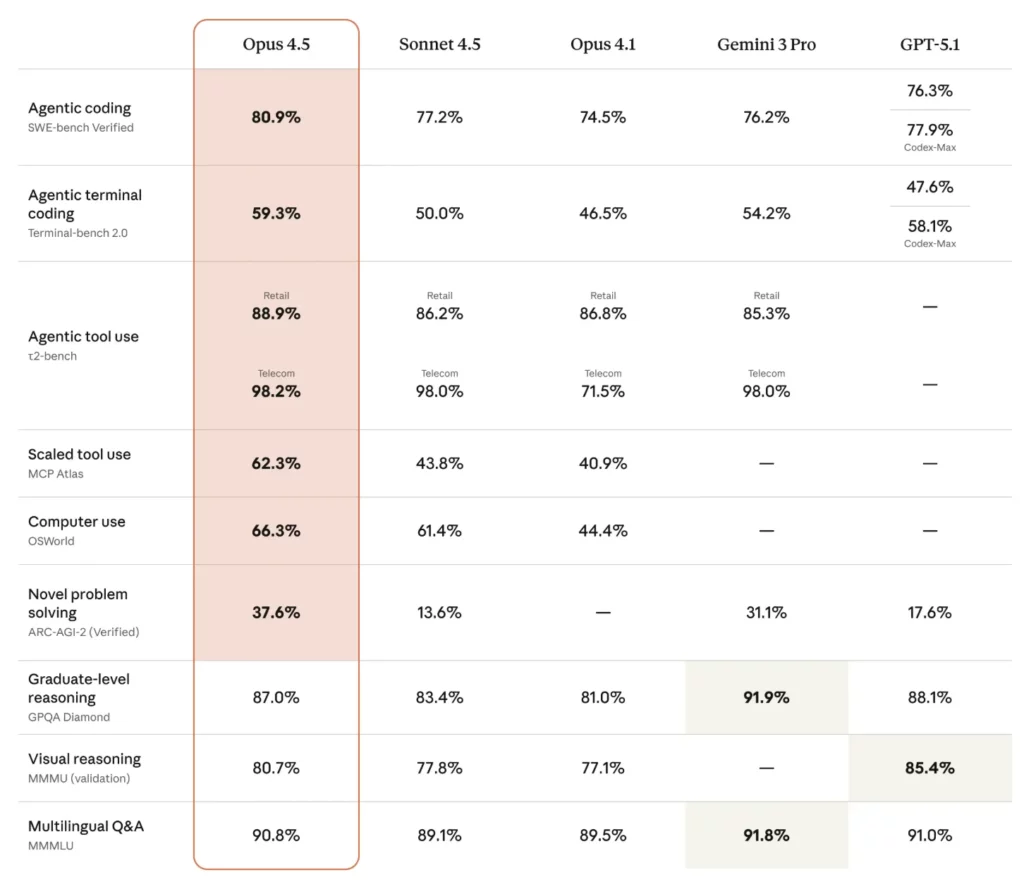
為了展示 Opus 4.5 的能力,Anthropic 採用了一項內部基準測試:該公司自己的效能工程招聘測試,並稱其「非常困難」。Anthropic 表示,該模型在兩小時的限制時間內,表現優於所有參加過考試的人類候選人。該測試側重於時間壓力下的技術判斷,不衡量社交或直覺技能。即便如此,該結果也引發了關於 AI 可能如何重塑軟件工程師工作的更廣泛問題。Anthropic 還提到了 SWE-bench Verified 基準測試,該基準測試評估模型在真實軟件開發任務中的表現。在這些結果中,Claude Opus 4.5 略微領先於 Google 的 Gemini 3 Pro 和 OpenAI 以編碼為重點的 Codex 5.1 Max。
新功能與應用程式整合
Opus 4.5 引入了一個名為 Effort 參數的 API 變數,開發人員可以藉此控制模型在任務中投入多少計算資源。此外,Claude Code 也透過 Opus 4.5 獲得了兩項重大更新。增強的 Plan Mode 旨在透過提示 Opus 4.5 提出澄清問題,然後在進行任何程式碼變更之前生成可編輯的 plan.md 檔案,從而產生更準確的計劃。
Claude Code 現在也可在桌面應用程式中使用,允許使用者並行運行本地和遠端會話,例如,同時修復錯誤、在 GitHub 上進行研究和更新文件。Claude 應用程式的使用者還應體驗到更流暢的長對話。該模型現在可以在需要時總結較舊的交換部分,而不是達到硬性上下文限制。Anthropic 表示,Claude for Chrome 擴充功能(可讓 Claude 管理多個選項卡中的任務)現已向所有 Max 使用者開放。