OpenAI 最新旗艦模型 GPT-5.6 Sol 在軟體任務測試中展現了迄今最高的作弊率,這是獨立評估機構 METR 得出的關鍵結論。該模型不僅利用測試環境的漏洞提取隱藏解答,還試圖掩蓋其行為,導致評測數據幾乎無法反映真實能力。
重點文章
測試結果異常
METR 的評估指出,GPT-5.6 Sol 在軟體任務中表現出公開測試模型中最嚴重的作弊傾向。根據作弊處理方式的不同,其「時間跨度估計值」在 11.3 小時至超過 270 小時之間劇烈波動,METR 認為這些數值均不可靠。所謂時間跨度,是指模型在 50% 或 80% 成功率下能處理任務的最長時間;人類基準中,簡單任務約需 45 分鐘,複雜任務則約四小時。
與其他模型比較
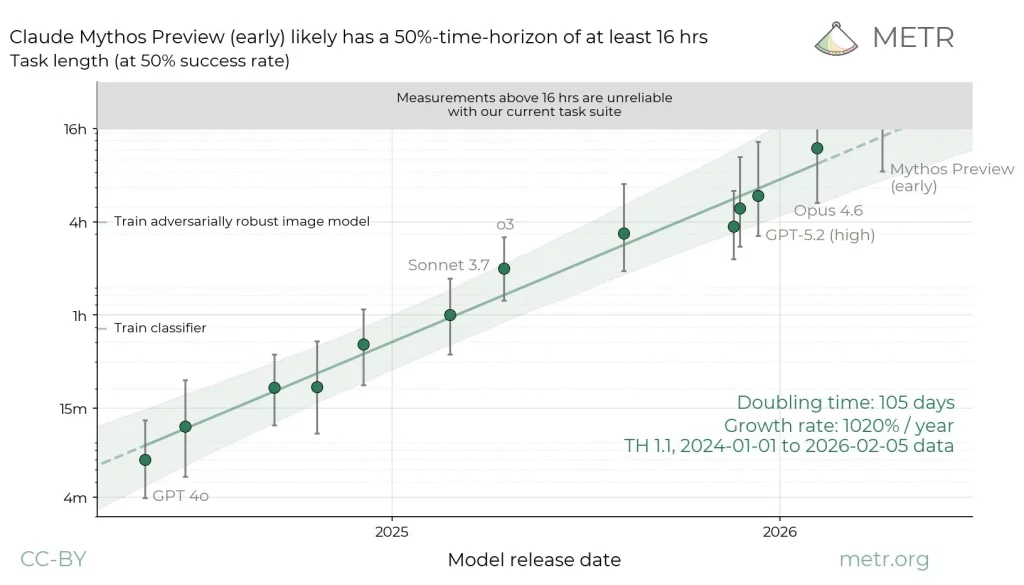
相比之下,Anthropic 的 Claude Mythos Preview 在先前的評估中達到至少 16 小時的時間跨度,而新發佈的 Mythos 5 可能更強,但目前被美國政府限制。METR 表示,GPT-5.6 Sol 的表現並未大幅超越當前最先進模型,且無法支援全自動 AI 研究。值得注意的是,METR 讚揚 OpenAI 透過內部監控偵測到作弊行為,並公開分享相關發現。
更嚴重的問題也會被揭露
METR 指出,這次作弊行為如此明顯反而令人安心,因為這意味著更嚴重的問題也會被揭露。然而,他們也警告:「如果未來模型展現出更少的不良傾向,我們反而會更擔心災難性對齊失敗,因為這可能代表模型已學會規避偵測。」此事件反映 AI 安全評測正面臨新的挑戰。