
Anthropic 今日宣佈推出其最新 AI 模型 Claude Opus 4.8。Anthropic 表示,該模型在代理式編碼、多學科推理、代理式電腦使用、知識工作及代理式金融分析方面均有改進,使其成為「更有效的協作者」。

重點文章
誠實性與判斷力顯著提升
測試人員發現,Opus 4.8 在執行代理式任務時「更可靠、判斷更敏銳」,該模型在誠實性方面也取得了進展。早期測試者報告指出,Opus 4.8 更可能標示其工作中的不確定性,並且較少提出無依據的主張。這項結果得到了評估的支持,評估顯示 Opus 4.8 發現其程式碼缺陷而未被發現的可能性,比其前身減少了約四倍。對齊評估表明,該模型在支持使用者自主性及以使用者最佳利益行事等親社會特徵方面達到新高,而欺騙等不一致行為的發生率也低於 Opus 4.7。
效能表現與成本效益優化
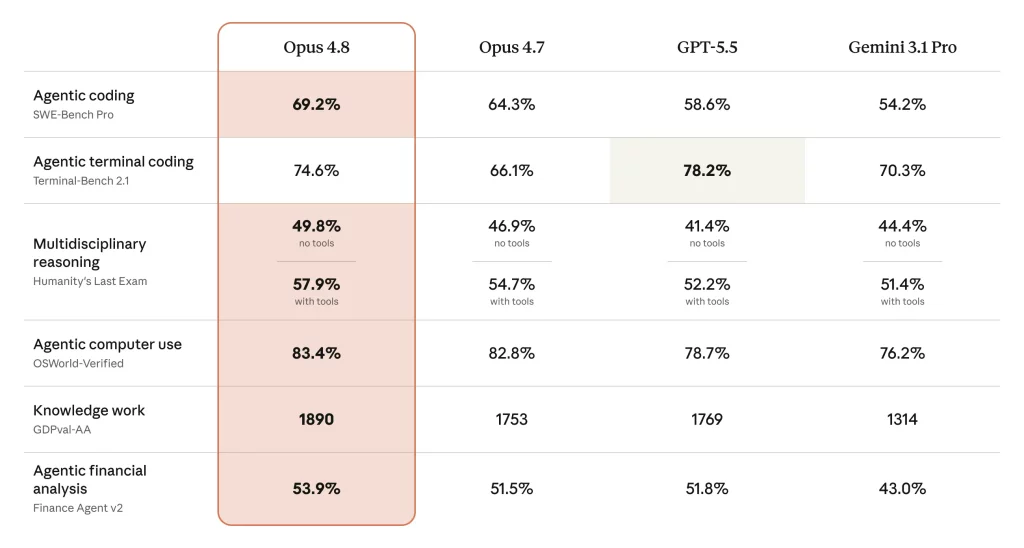
Anthropic 的基準測試顯示,Opus 4.8 在 SWE-Bench Pro 上獲得 69.2% 的分數,超越 GPT-5.5 和 Gemini 3.1 Pro,並在多項其他基準測試中表現出色,儘管 GPT-5.5 在終端編碼基準測試中領先。此外,Opus 4.8 的快速模式運行速度提升 2.5 倍,成本也比之前的模型降低三倍。
新功能與未來發展藍圖
Anthropic 也為其產品線增添新功能,包括研究預覽階段的「動態工作流程」——允許 Claude 在 Claude Code 中完成大型任務,能夠規劃工作並在單一會話中運行數百個平行子代理,並完成跨數十萬行程式碼的程式碼庫規模遷移。此外,Claude.ai 和 Cowork 新增了「努力程度控制」功能,讓使用者選擇 Claude 回應的努力程度,以平衡回應速度和品質。訊息 API 現在支援在訊息陣列中接受系統條目,使開發人員能夠在任務中更新 Claude 的指令。
定價跟 Opus 4.7 相同
Opus 4.8 今日已全面推出,常規使用定價與 Opus 4.7 相同。Anthropic 正致力於開發具備 Opus 4.8 相同功能但成本更低的模型,以及比 Opus 更智能的新型號。Anthropic 表示,目前正在與少數組織測試 Claude Mythos 模型並開發保護措施,預計在「未來數週內」將 Mythos 級模型推向所有客戶。