
在科技界,我們習慣了「一分錢、一分貨」的硬道理。想要極致的推理智商?那就得忍受高昂的 API 成本和漫長的等待時間;想要極速回應?那就必須在智力上做出妥協。然而,看過最新 Artificial Analysis 的數據以及實際體驗後,這條鐵律被徹底打破了。老實說,這次最令我感到驚豔與震撼的,是 Gemini 3.5 Flash 在 Agentic 編程(智能體編程)上的表現與驚人速度。這款模型表現出的潛力,讓我對 Google 的模型佈局徹底改觀。

如果用簡單一句話來總結當前的局勢:Gemini 3.5 Flash 的聰明程度直逼 Gemin 3.1 Pro 頂級旗艦模型,價格比它便宜,而重點是速度超快,把所有人都甩在後頭!
重點文章
降維打擊的智商與「破格」的性價比
從「智能 vs 運行成本(Intelligence vs. Cost to Run)」的分析圖表中可以看到,Gemini 3.5 Flash 展現出了極其恐怖的性價比:
- 智力直逼頂級旗艦: 它的 Artificial Analysis Intelligence Index 評分高達 55.5 以上,雖然比起當前地表最強的 GPT-5.5 (xhigh) 或 Claude Opus 4.7 (max) 略低了一點點,但這差距在實際應用中微乎其微。
- 成本卻是破天荒的低: 它的運行成本僅在 1.5k 左右的水準,與 GPT-5.3 Codex (xhigh) 相當。這意味著你用極低的「輕量級模型價格」,買到了接近「頂級旗艦模型」的智商。
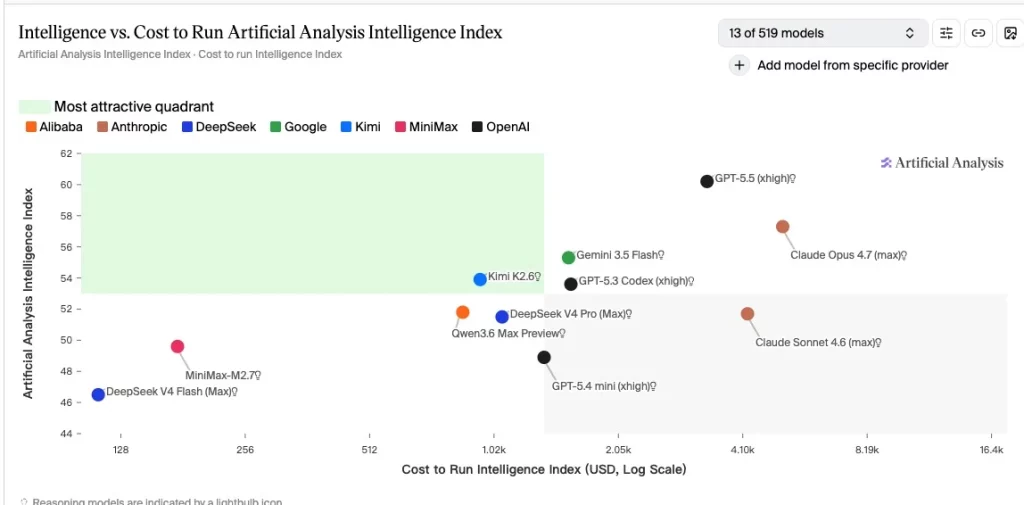
最讓人難以置信的是,這不是 Gemini Pro,而是 Flash 模型! Google 竟然成功把接近 Gemini 3.5 Pro 等級的智力,強行壓縮並塞進了 Flash 的價格與速度框架裡,這在過去的 AI 發展史中簡直難以想像。
速度稱王:每秒 277 輸出 Token 的絕對領域
如果說高性價比讓人心動,那麼 Gemini 3.5 Flash 的輸出速度就是讓人感到震撼。在「輸出速度(Output Speed)」的對比中,Gemini 3.5 Flash 的成績是誇張的 每秒 277 個 Token (277 tokens/s)。
對比其他競爭對手:
- GPT-5.4 mini (xhigh): 168 tokens/s(Gemini 3.5 Flash 比它快了將近 65%!)
- DeepSeek V4 Flash (Max): 105 tokens/s
- Claude Sonnet 4.6 (max): 62 tokens/s
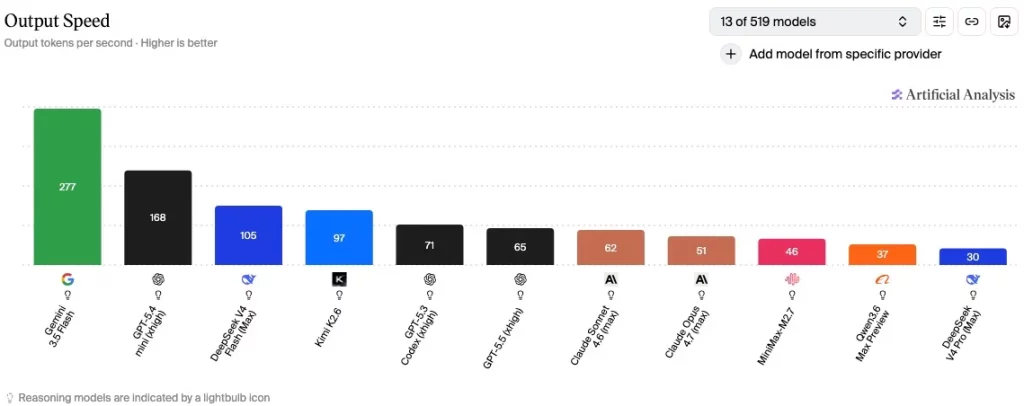
在運行需要頻繁交尾、反覆修正代碼的 Agentic 編程時,速度就是生命。Gemini 3.5 Flash 這種近乎「秒回」的吞吐量,能讓 AI Agent 在幾秒鐘內完成數輪的「思考、編寫、測試、除錯」閉環,將開發效率提升到全新維度。
總結:Agentic 時代的效率神兵
過去在開發 AI Agent 或進行複雜編程任務時,我們總是在 Claude 的精準、GPT 的嚴謹與小型模型的速度之間痛苦抉擇。
但 Gemini 3.5 Flash 的出現終結了這個局面。它用 Flash 的速度與價格,承載了直逼 Pro 的智力水準。這不僅僅是一次常規的性能升級,更是 Google 衝著整個大模型市場、特別是針對開發者生態發動的一場「降維打擊」。這一次,Google 確實拿出了令人徹底改觀的誠意與實力!
| 計費項目 (Per 1M tokens) | Gemini 3.5 Flash | Gemini 3.1 Pro (Preview) |
|---|---|---|
| Input Price | $0.75 USD |
$2.00 USD (Prompt ≤ 200k tokens) $4.00 USD (Prompt > 200k tokens) |
| Output Price | $4.50 USD |
$12.00 USD (Prompt ≤ 200k tokens) $18.00 USD (Prompt > 200k tokens) |