
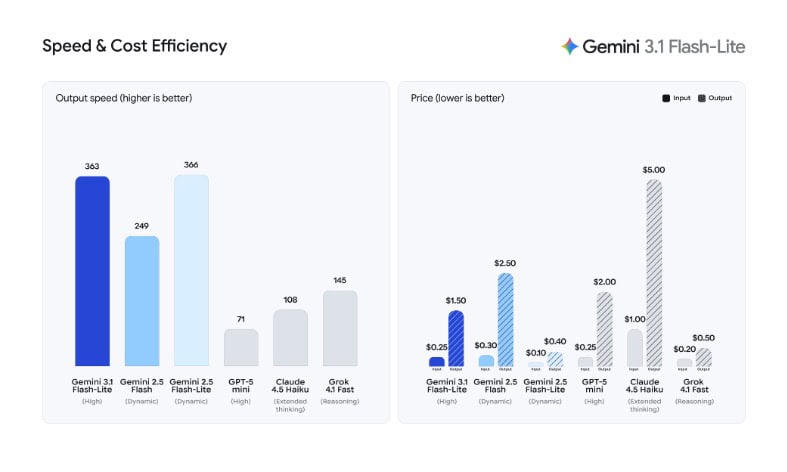
Google 近期推出了 Gemini 3.1 Flash-Lite 預覽版,這是 Gemini 3 系列中最快且價格最平實的模型。根據 Artificial Analysis 的數據顯示,該模型在智能指數上獲得 34 分,較前代 Gemini 2.5 Flash-Lite 提升了 12 分。儘管性能大幅躍升,但其運作速度仍維持在高水準,每秒可產出超過 360 個 Token,平均反應時間僅需 5.1 秒。
重點文章
多模態理解能力超越同級產品
在 Arena.ai 排行榜中,Gemini 3.1 Flash-Lite 的 Elo 分數達到 1432 分,在推理與多模態理解方面的表現優於同級別的其他模型。在科學知識測試 GPQA Diamond 中,其得分為 86.9%,而在多模態理解與推理測試 MMMU Pro 中則達到 76.8%,表現甚至超越了上一代的 Gemini 2.5 Flash 大型模型。此外,其首個 Token 的反應速度比 Gemini 2.5 Flash 快 2.5 倍,整體輸出速度則提升了 45%。
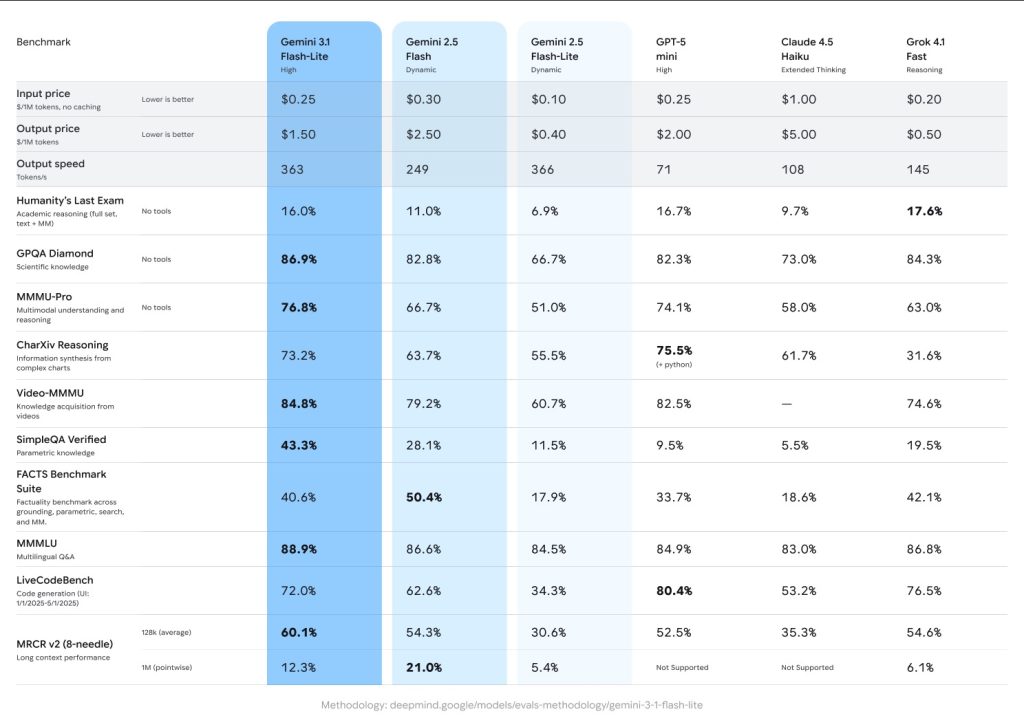
輸出定價漲幅超過三倍
隨著性能與速度的進步,使用成本也隨之增加。Gemini 3.1 Flash-Lite 的輸出定價漲幅超過三倍,每百萬輸入 Token 的費用由 0.10 美元調升至 0.25 美元,而每百萬輸出 Token 的費用則從 0.40 美元大幅增加至 1.50 美元。開發者可以根據需求調整模型的思考程度,使其既能處理如翻譯等大量簡單任務,也能勝任構建用戶介面等複雜工作。
支援百萬長文本上下文處理
該模型維持了 100 萬個 Token 的長上下文窗口,在多語言問答與程式碼生成等測試中也展現出強大的競爭力。Google 表示,這款模型現已在 Google AI Studio 及 Vertex AI 開放測試,為開發者提供更平衡的 AI 解決方案。