
近日很多盛讚 Claude Code的言論,不過作為長期用戶,這幾天 Opus 4.5 有明顯「降智」問題。如何得知一個模型有沒有被降智?長期用戶會感受得到,一些預期它能 1 Take 完成的工作,卻要做 2-3 次才達標。
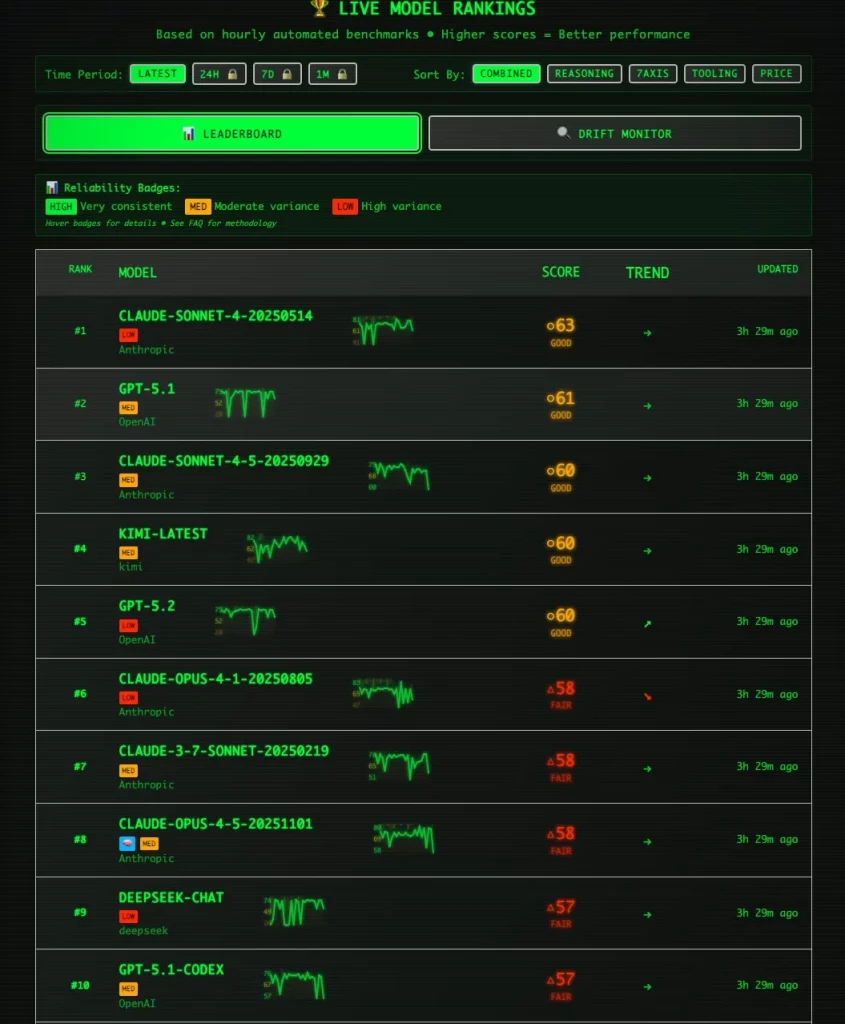
很主觀?對!不過,給大家介紹一個名為 Stupid-Meter 的網站。 它會分析當前各大主流模型的可靠度,而且不停更新。
執筆之時,可靠度最高是 SONNET 4 (不是 4.5),而 GPT 5.2 排第二,至於 Opus 4.5 只排第 5。至於 Gemini 3 Pro Preview 則排第10。我不太肯定 SONNET 4 是否真的比 4.5 穩定,但筆者認為近期GPT 5.2 Codex(High)比Opus 4.5 可靠。至於Gemini 3 Pro 只排第 10 也很合理,誰用誰知道。
AI 模型有時會因為用戶人數太多,需求太高而降低其輸出質素。當然,也有可能因為一些 bug 或故障,影響輸出表現。因此,經常查看一下 Stupid-Meter,再決定用什麼模型是一個良好的習慣。