中國 AI 實驗室 Deepseek 發佈了 V3.2,這是一個新的語言模型,在關鍵基準測試和推理任務中與 GPT-5 和 Google 的 Gemini 3 Pro 相匹敵。

重點文章
V3.2 的改進
Deepseek 團隊發現目前開源模型的三個主要缺陷:長文本處理效率低下、自主代理能力薄弱,以及後期訓練投入不足。根據新發佈的技術報告,V3.2 通過重新設計的注意力架構和大規模的後期訓練來解決這些問題。該公司在 9 月份發佈了一個名為 V3.2-Exp 的初步版本,預告了這些功能。
DSA 技術
核心升級是 Deepseek Sparse Attention (DSA)。標準模型會為每個新的響應重新檢查每個先前的 token,這對於長時間的對話來說是一個計算量很大的過程。DSA 使用一個小型索引系統來識別文本歷史中的重要部分。通過只讀取必要的內容,該模型在不犧牲品質的情況下降低了計算成本。Deepseek 表示,這大大加快了長輸入的處理速度,但該公司沒有分享具體的數字。
基準測試結果
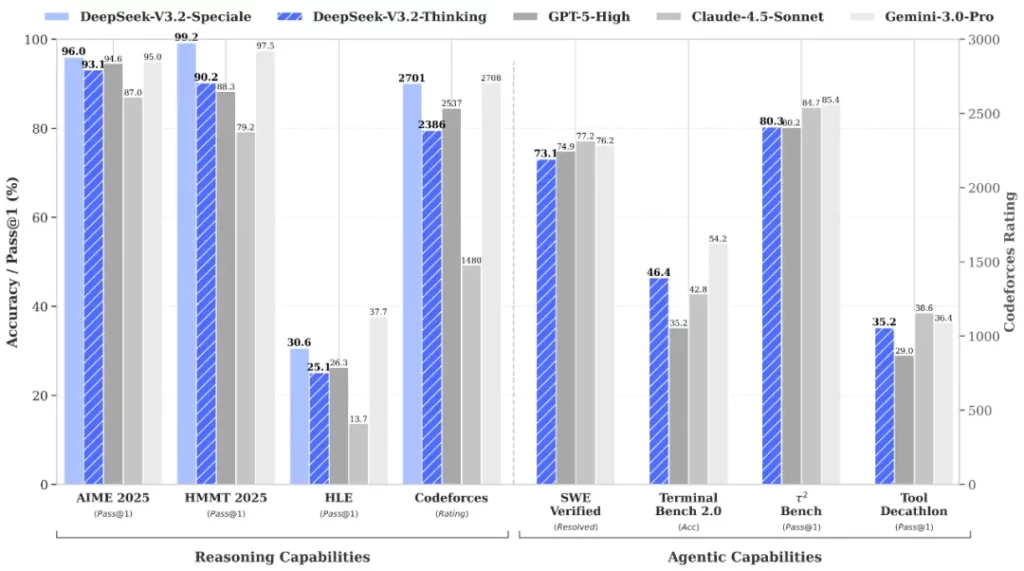
在 AIME 2025 數學競賽中,V3.2 的得分為 93.1%,僅次於 GPT-5 (High) 的 94.6%。OpenAI 此後發佈了 GPT-5.1 和更新的 Codex 模型。在編程方面,V3.2 在 LiveCodeBench 上的命中率為 83.3%,再次僅次於 GPT-5 的 84.5%。Google 的 Gemini 3 Pro 仍然是領先者,在 AIME 中的得分為 95.0%,在 LiveCodeBench 中的得分為 90.7%。在使用真實 GitHub issue 測試軟體開發的 SWE Multilingual 上,V3.2 解決了 70.2% 的問題,優於 GPT-5 的 55.3%。它在 Terminal Bench 2.0 上也優於 GPT-5(46.4% 對 35.2%),但落後於 Gemini 3 Pro(54.2%)。