首度完整上線的 Grok 4.1 已正式登陸 grok.com、X 平台以及 iOS 與 Android 應用程式,結束過去兩週的安靜上線期。此次更新被視為 xAI 在打造更強大且更貼近人類互動的 AI 系統上,邁出的重要一步。

重點文章
主要更新內容
Grok 4.1 可在 Auto 模式自動啟用,也能在型號選單中手動切換。xAI 表示這次更新著重於提升實際使用體驗,包括創造力、情感理解、對話風格與協作能力,同時維持先前版本的高準確度與可靠性。開發過程大量依賴原本為 Grok 4 建置的大規模強化學習系統,並透過高階推理模型作為自動化評估工具,以大量評分與微調模型表現,反映出業界以強模型訓練更強模型的趨勢。
效能表現與排名
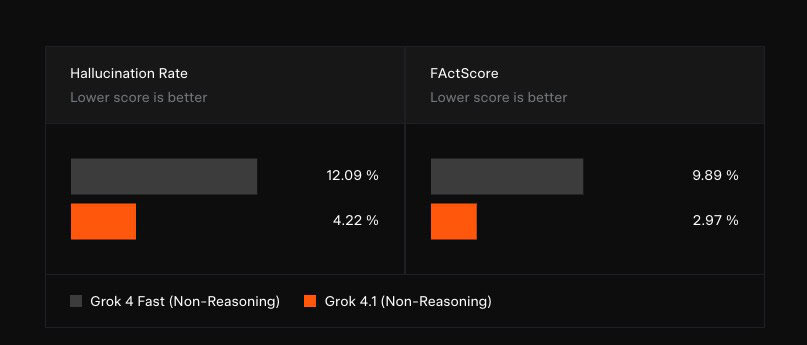
在 11 月 1 日至 14 日的安靜上線期間,xAI 將越來越多的真實流量導向 Grok 4.1,並透過盲測比較結果顯示,新版本在實際使用者互動中有 64.78% 的偏好率。xAI 表示 Grok 4.1 已在多項公開能力排行榜名列前茅,其中推理版本 “quasarflux” 的 Elo 分數達 1483,領先最強的非 xAI 競爭者,而不使用推理 token 的快速回應版本 “tensor” 依然排名第二,顯示其在速度與準確度間取得罕見的平衡。
情感理解與創造力提升
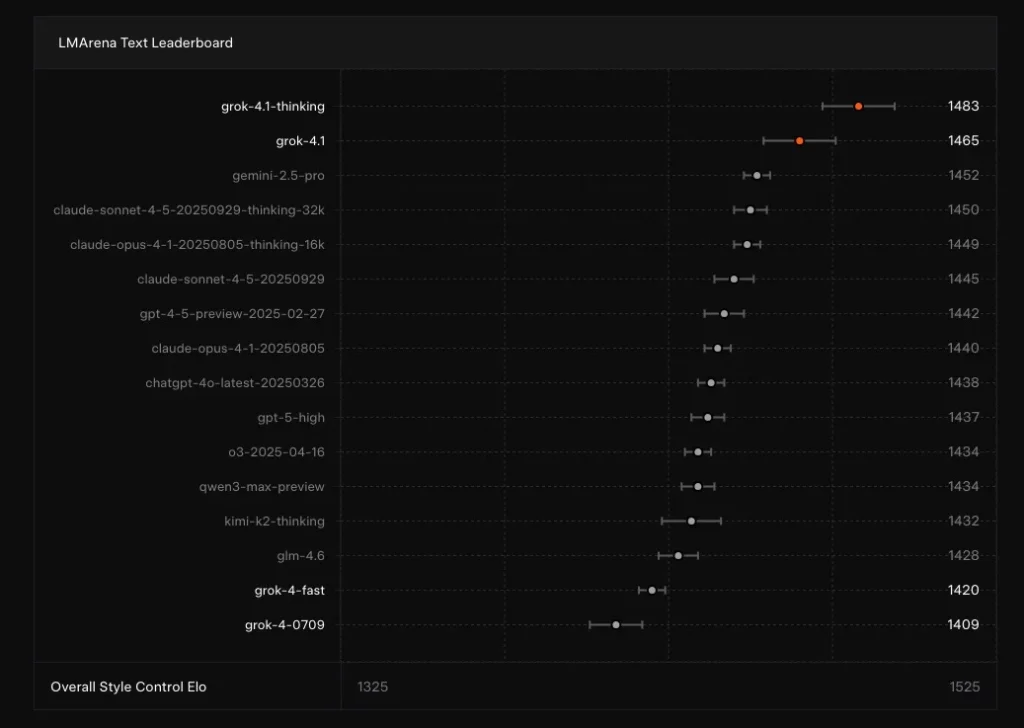
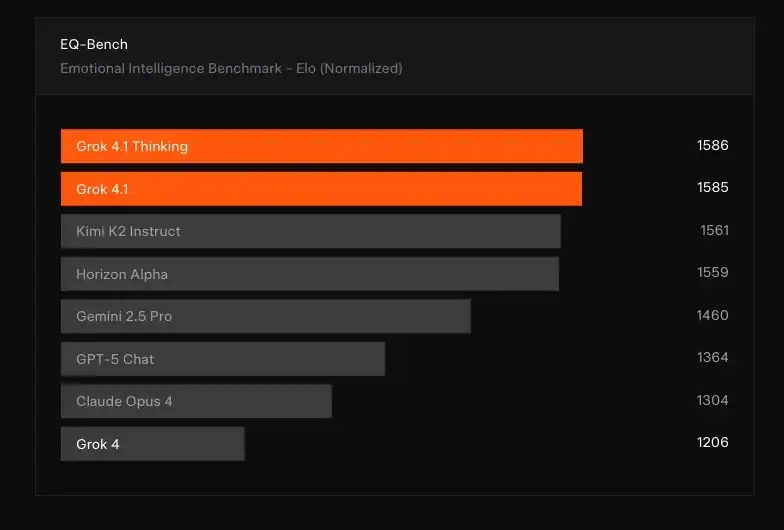
Grok 4.1 在 EQ-Bench3 的情感理解測試中取得最高分,展現更深層的同理心與處理複雜情緒的能力。官方示例中,當使用者表示「I miss my cat so much it hurts」時,Grok 4.1 能以更貼近人心的語氣回應。模型在 Creative Writing v3 測試中也名列前段,其敘事風格更具個性與文化敏感度,呼應 Grok 早期以幽默風格定位的取向,同時具備更廣泛的內容創作應用潛力。
幻覺率下降與後續影響
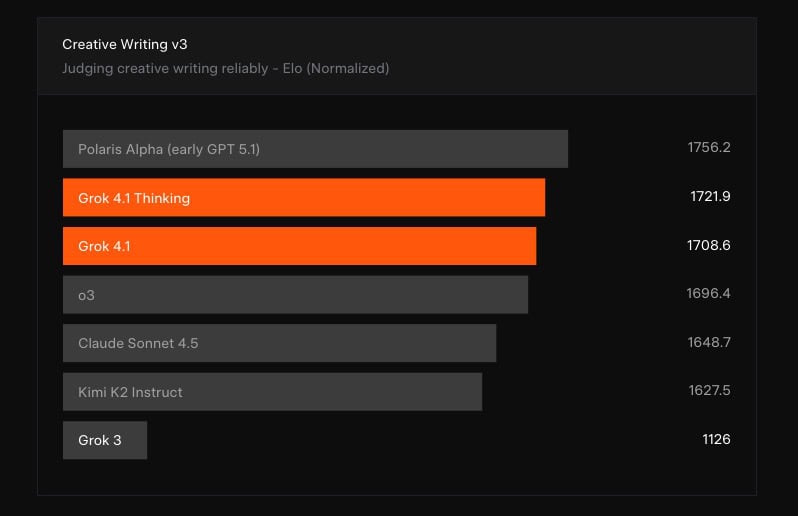
在具網路搜尋功能的快速回應模式下,Grok 4.1 的資訊錯誤率由 12.09% 降至 4.22%,在 FActScore 基準中的錯誤率也降至 2.97%,顯示在真實查詢場景中更可靠。這項進展對企業採用與高風險情境特別重要。整體而言,Grok 4.1 的推出意味著 xAI 正加速追趕領先業者,並透過自動化評估流程向更高效的模型研發方式邁進,使 Grok 逐步從對話產品轉型為可支援消費者、企業與代理型任務的基礎 AI 平台。