小米最新推出的 MiMo-7B 模型,瞄準數學與程式推理任務,展示小參數語言模型亦能匹敵甚至超越大型對手的潛力。透過獨特的訓練策略與強化學習設計,MiMo-7B-RL 在多項評測中表現亮眼,成功在「小而強」的趨勢中脫穎而出。

重點文章
小參數模型的新挑戰
與現今多數採用 32B 參數的開源推理模型不同,小米的 MiMo-7B 採用僅 70 億參數的架構,透過針對性的前後訓練策略強化效能。研究團隊表示,模型預訓練使用高達 25 兆 token 的語料,重點在於讓模型從早期便熟悉數學與程式邏輯。此外,小米亦開發數學公式與程式碼抽取工具,支援 HTML 與 PDF 格式,並導入三階段資料混合流程,以強化模型對合成任務的理解能力。
70% 邏輯數據+長上下文處理能力
在預訓練最後階段,數學與程式碼資料占比被拉高至 70%,同時上下文長度延伸至 32,768 token,使 MiMo-7B 能處理更長篇、複雜的推理任務。另一大亮點是「多 Token 預測(Multi-Token Prediction, MTP)」技術,讓模型一次預測多個後續 token,加快推理速度並提升精準度。
引入強化學習與困難度測試獎
完成預訓練後,小米對兩種版本進行強化學習微調:MiMo-7B-RL-Zero 是從原始模型直接訓練,而 MiMo-7B-RL 則建立於已經精調過的 SFT 版本。訓練資料涵蓋 13 萬個可驗證的數學與程式任務。針對程式類任務的獎勵系統更導入「Test Difficulty Driven Reward」,依題目難度調整測試案例的權重,解決稀疏回饋問題。為提高訓練穩定性,MiMo-7B 同時使用「Easy Data Re-Sampling」策略,減少模型已熟練任務的出現頻率。
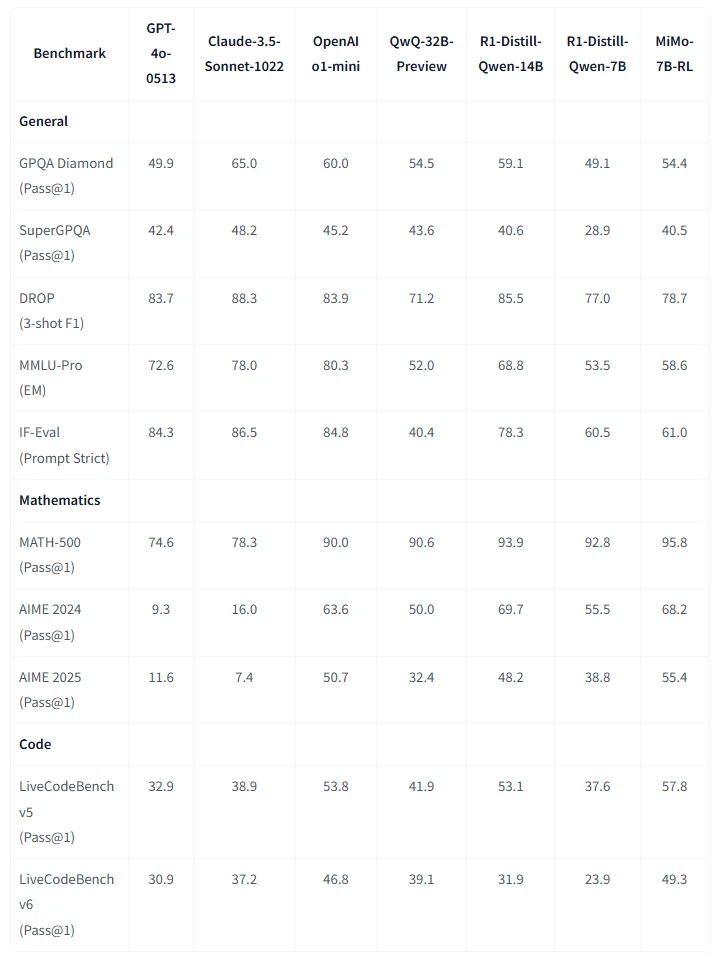
基準測試結果展現強勁競爭力
根據報導,MiMo-7B-RL 在 AIME 2025 數學基準測試中取得 55.4 分,超越 OpenAI o1-mini 的 50.7 分;在 LiveCodeBench v5 中更拿下 57.8% 的成績,領先 Alibaba 的 QwQ-Preview(32B)將近 16%。雖然 Alibaba 最新的 Qwen3-30B-A3B 型號拿下 62.6% 更高分,但 MiMo-7B-RL 已成功證明小型模型在推理任務中的高度潛力,也突顯市場正加速走向「小而精」的模型研發方向。